
Как написать файл Robots.txt ... Это искусство! (Wordpress Focus)
- Что такое файл Robots.txt? Почему это важно?
- Пользовательский агент Robots.txt
- The Robots.txt Запретить правило
- Запрет определенного URL
- Запрещение определенной подпапки
- Запрет URL-адресов по строке запроса
- Общие подпапки WordPress и строки запросов для запрета
- Правило «Разрешить» в файле Robots.txt
- Правило «NoIndex» для Robots.txt
- Ссылка на ваш XML Sitemap в файле Robots.txt
- Тестирование правил Robots.txt в консоли поиска Google
- Просмотреть как Google
- Robots.txt Tester
- Дополнительные инструменты тестирования Robots.txt
- Другие замечания Robots.txt
- Внешние ссылки на запрещенные URL
- Заблокированные страницы по-прежнему отображаются в результатах поиска
- URL отслеживания кампании PPC
- Отфильтрованные / граненые URL и ловушки для сканирования
- Используйте мой оптимизированный файл WordPress Robots.txt
Одним из наиболее запутанных аспектов SEO является изучение того, как написать файл robots.txt, чтобы поисковые системы эффективно сканировали ваш сайт и индексировали только контент, который вы хотите найти в результатах поиска. Это руководство предназначено для того, чтобы сделать файл robots.txt для вашего сайта более понятной задачей.
В этом руководстве также рассматриваются общие оптимизации robots.txt для веб-сайтов WordPress. WordPress CMS составляет почти 20% всех сайтов , что делает его самой распространенной CMS в мире. Тем не менее, большая часть этого совета может быть применена к другой CMS, если учитывать различные структуры URL.

Что такое файл Robots.txt? Почему это важно?
Файл robots.txt - это просто файл «.txt», который загружается в корневую папку (обычно через FTP) и содержит список директив сканирования, которые вы предоставляете поисковым системам, когда они посещают ваш сайт для сканирования. Посмотреть мой Вот если вы не знакомы с тем, как это выглядит. Это чертовски скучно.
Доступ к файлу robots.txt на вашем веб-сайте - это первый шаг в процессе сканирования поискового бота, а оптимизация файла robots.txt служит вашей первой линией защиты, гарантируя, что боты поисковой системы разумно тратят свое время при сканировании вашего веб-сайта. Это особенно важно для больших веб-сайтов, где бюджет сканирования поискового бота может не обеспечить полный обход веб-сайта.
Пользовательский агент Robots.txt
Правила в файле robots.txt могут быть адресованы либо всем искателям, либо определенным искателям, а протокол User-agent используется для указания искателя, к которому относятся ваши правила. Он должен быть указан выше ваших правил (для каждого агента пользователя).
При использовании протокола User-Agent: * правила будут применяться ко всем сканерам, однако здесь приведены другие распространенные пользовательские агенты, которые вам может понадобиться при написании правил для определенных сканеров в файле robots.txt. Вы можете найти более полный список Вот ,
- Google (General) - Пользователь-агент: Googlebot
- Google (Изображение) - Пользователь-агент: Googlebot-Image
- Google (Mobile) - Пользователь-агент: Googlebot-Mobile
- Google (Новости) - Пользователь-агент: Googlebot-News
- Google (Видео) - Пользователь-агент: Googlebot-Video
- Bing (General) - Пользователь-агент: Bingbot
- Bing (General) - Пользователь-агент: msnbot
- Bing (Изображения и видео) - Пользователь-агент: msnbot-media
- Yahoo! - Пользователь-агент: slurp
The Robots.txt Запретить правило
Основным правилом оптимизации файла robots.txt является правило «запретить». Он дает указание поисковым системам НЕ сканировать определенный URL, определенную папку или коллекцию URL, определенные правилом строки запроса (часто это правило подстановочного знака, использующее звездочку). Это также приведет к тому, что URL-адреса не будут проиндексированы в поисковых системах (или будут «подавлены», если они уже проиндексированы).
Правило запрета следует использовать с URL-адресами относительного пути, и оно может контролировать только поведение поискового бота на вашем веб-сайте. Он отформатирован так:
Disallow: правило идет сюда
Часть «правило здесь» должна быть заменена тем правилом, которое вы хотите применить. Опять же, это может быть конкретный URL-адрес, конкретная подпапка или набор URL-адресов, определенных правилом строки запроса. Вот несколько примеров каждого:
Запрет определенного URL
Следующее правило будет указывать поисковым системам не сканировать URL-адрес по адресу http://www.domain.com/specific-url-here/.
Disallow: / specific-url-here /
Запрещение определенной подпапки
Следующее правило будет указывать поисковым системам не сканировать любые URL-адреса в подпапке, расположенной по адресу http://www.domain.com/subfolder/.
Disallow: / подпапка /
Запрет URL-адресов по строке запроса
Следующее правило будет указывать поисковым системам не сканировать любые URL-адреса, начинающиеся с http://www.domain.com/confirmation, независимо от того, какие символы появляются после этой начальной части URL-адреса. Это может быть полезно, если у вас есть несколько URL-адресов, которые построены с похожей структурой, но вы не хотите, чтобы поисковые системы сканировали или индексировали их (т. Е. Страницы подтверждения для форм получения по электронной почте).
Запретить: / подтверждение *
Примечание. Вы должны быть осторожны с этим правилом, поскольку можете непреднамеренно запретить сканирование важных страниц, которые вы действительно хотите, чтобы поисковые системы сканировали и индексировали.
Общие подпапки WordPress и строки запросов для запрета
Существует общий набор подпапок, которые являются родными для WordPress CMS, и вы хотите ограничить сканирование поисковых систем. Вот краткий список папок для использования правила «Запретить»:
- WordPress Admin - / wp-admin /
- Включает WordPress - / wp-includes /
- Контент WordPress - / wp-content /
- Внутренние результаты поиска - /? S = *
Однако для сайтов WordPress важно разрешить поисковым системам сканировать вашу / wp-content / uploads / подпапку, чтобы ваши изображения могли быть проиндексированы. Таким образом, вам нужно правило, такое как следующее:
Разрешить: / wp-content / uploads /
Правило «Разрешить» в файле Robots.txt
Это правило стало намного популярнее, когда Google объявленный что он хочет иметь возможность сканировать CSS и javascript, чтобы отобразить страницу так, как ее видит пользователь. Простым подходом было бы добавить следующие правила в User-agent: раздел Googlebot вашего файла robots.txt.
Пользователь-агент: Googlebot Разрешить: * .js * Разрешить: * .css *
Однако я обнаружил, что Google не всегда соблюдает эти правила «Разрешить», если у вас есть файлы CSS и javascript, расположенные в разных подпапках.
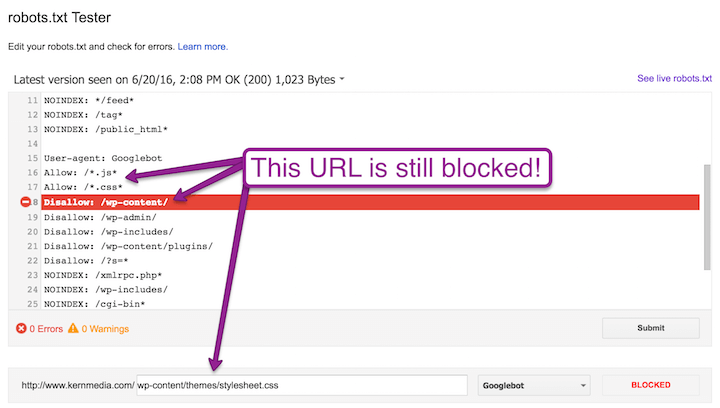
Следующие подпапки WordPress обычно запрещены для сканирования, но в них могут быть файлы javascript и CSS, к которым Google не сможет получить доступ, если вы не предоставите им конкретные команды «allow»:
- / WP-администратора /
- / WP-включает /
- / WP-содержание / темы /
- / WP-содержание / плагины /
Чтобы разблокировать файлы javascript и CSS в этих подпапках, в дополнение к файлам javascript и CSS, не включенным в эти подпапки, необходимы следующие правила:
Пользователь-агент: Googlebot Разрешить: /*.js* Разрешить: /*.css* Разрешить: /wp-content/*.js* Разрешить: /wp-content/*.css* Разрешить: / wp-includes / *. js * Разрешить: /wp-includes/*.css* Разрешить: /wp-content/plugins/*.css* Разрешить: /wp-content/plugins/*.js* Разрешить: / wp-content / themes / *. css * Разрешить: /wp-content/themes/*.js*
Правило «NoIndex» для Robots.txt
Google заявил, что они могут соблюдать правило «Nondex» в вашем файле robots.txt, согласно этому Hangouts для веб-мастеров Google с Джон Мюллер известный аналитик Google Webmaster Trends Analyst.
Тем не менее, Джон Мюллер заявил через месяц в Twitter, что не советует использовать правило «NOINDEX» в файле robots.txt.
Таким образом, использование этого правила зависит от вас. Он не заменяет лучшую практику управления индексацией с помощью мета-роботов и тегов X-robots, однако он может быть полезен (только с Google) в крайнем случае, если технические ограничения оставят его в качестве последнего средства.
Правило простое в применении. Вот несколько примеров:
NOINDEX: /xmlrpc.php* NOINDEX: / wp-includes / NOINDEX: / cgi-bin * NOINDEX: * / feed * NOINDEX: / tag * NOINDEX: / public_html *
Ребята из Stone Temple Consulting провели тестовое задание и определил, что «в конечном итоге директива NoIndex в Robots.txt довольно эффективна». У меня был хороший успех с использованием правила NoIndex в моем файле robots.txt, чтобы также извлечь страгглер / тег / страницы из индекса Google. Поэтому не стесняйтесь использовать это правило для дальнейшей оптимизации файла robots.txt. Однако учтите, что это работает только для Google, который может не уважать его в любой момент времени.
Ссылка на ваш XML Sitemap в файле Robots.txt
Поисковые системы также будут искать карту сайта XML в вашем файле robots.txt. Если у вас есть несколько карт сайта XML, таких как карта сайта XML видео, в дополнение к вашей основной карте сайта XML, то вы захотите связать и то и другое здесь. Файлы Sitemap в формате XML должны быть связаны в файле robots.txt следующим образом (обычно в нижней части карты сайта):
Карта сайта: http://www.domain.com/sitemap_index.xml Карта сайта: http://www.domain.com/video-sitemap.xml
Тестирование правил Robots.txt в консоли поиска Google
Google предоставляет два инструмента в Google Search Console которые отлично подходят для тестирования ваших правил файла robots.txt, чтобы убедиться, что они соблюдаются и что вы правильно разблокируете javascript, CSS и другие важные файлы, которые Google должен сканировать, чтобы визуализировать страницу так, как ее видит пользователь.
Просмотреть как Google
Просмотреть как Google инструмент в Google является отличной отправной точкой для обнаружения любых заблокированных ресурсов, которые Google не может сканировать и отображать из-за правил файла robots.txt. Обычно сообщаемыми проблемами являются файлы JavaScript, CSS-файлы и заблокированные изображения.
При использовании этого инструмента обратите внимание на любые заблокированные ресурсы для тестирования изменений в ваших правилах файла robots.txt. Вы хотите, чтобы у вас не было заблокированных ресурсов или только внешние заблокированные ресурсы (которыми вы не можете управлять). На следующем снимке экрана показано, что только два внешних ресурса в моем файле robots.txt не были просмотрены Google. Это хорошо.

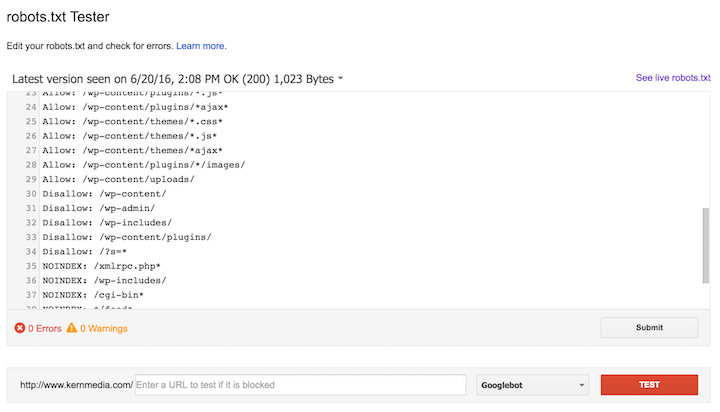
Robots.txt Tester
После определения заблокированных ресурсов используйте Robots.txt Tester инструмент для проверки реализации новых правил и определения, разрешено ли роботу Google сканировать их или нет. Как только ваши правила будут завершены, добавьте их в ваш файл robots.txt. Вот как выглядит инструмент:
Дополнительные инструменты тестирования Robots.txt
Спасибо Максу Прину, Адаму Одетту и команде Merkle за создание этого супер потрясающий инструмент тестирования что позволяет проверять заблокированные ресурсы, не имея доступа к учетной записи веб-сайта Google Search Console. Они даже работают над специальным запросом (от вашего истинного), чтобы предоставить ваши собственные измененные правила файла robots.txt. Это позволит нам увидеть, как робот Google и другие боты реагируют (в отношении заблокированных ресурсов) на пользовательские изменения правил до их запуска (или для работы на сайте разработки). Определенно проверьте это.
Другие замечания Robots.txt
Как человек, который ежедневно просматривает результаты поиска Google, следит за техническими новостями SEO и помогает клиентам в сложных технических проектах SEO, я столкнулся с некоторыми другими проблемами, связанными с файлами robots.txt, которые могут оказаться для вас полезными.
Внешние ссылки на запрещенные URL
Если поисковые системы найдут внешнюю ссылку на URL-адрес, запрещенный через файл robots.txt, они могут проигнорировать ваше правило и в любом случае сканировать страницу из-за внешнего сигнала. Вот что конкретно говорит Google ( источник ):
Однако robots.txt Disallow не гарантирует, что страница не будет отображаться в результатах: Google по-прежнему может принять решение, основываясь на внешней информации, такой как входящие ссылки, что она актуальна. Если вы хотите явно заблокировать индексацию страницы, вам следует использовать метатег noindex robots или HTTP-заголовок X-Robots-Tag. В этом случае вам не следует запрещать страницу в robots.txt, потому что страница должна быть просканирована, чтобы тег можно было увидеть и повиноваться.
Это последнее предложение дает дополнительную информацию. Если вы хотите, чтобы страница была удалена из индекса Google, она должна иметь метатег «noindex» в теге <head> или X-Robots-Tag в заголовке HTTP. Имейте это в виду, если вы пытаетесь удалить несколько низкокачественных URL-адресов из индекса Google, и подумайте, когда вы покажете запретить их через файл robots.txt.
Заблокированные страницы по-прежнему отображаются в результатах поиска
Страницы на вашем сайте, которые были проиндексированы в поисковых системах до того, как они были запрещены через ваш файл robots.txt, могут по-прежнему появляться в индексах поисковых систем при выполнении запроса site: domain.com , но под ними есть сообщение (например, в Google), что гласит «Описание этого результата недоступно из-за robots.txt этого сайта». Чтобы получить их, нужно разблокировать их в файле robots.txt (удалить правило «disallow») и применить мета-тег roots «noindex» (или тег X-robots). Как только вы подтвердите, что поисковые системы выпали из своего индекса, вы можете снова заблокировать их в файле robots.txt.
URL отслеживания кампании PPC
Будьте осторожны при использовании подстановочных знаков в ваших правилах «Запретить», когда вы используете URL-адреса отслеживания кампаний для платных поисковых / социальных кампаний, работающих с Google, Bing, Facebook и т. Д. «Рекламные роботы» для этих служб должны будут сканировать URL-адреса отслеживания кампаний. так что вы не можете их заблокировать.
По этой причине вы захотите добавить раздел агента пользователя для каждого «рекламного бота», который содержит правило «Разрешить» для каждого шаблона URL отслеживания кампании (т. Е. - Разрешить: / *? Utm_medium = * ).
Ниже приведены примеры правил для Google, Bing и Facebook, в качестве примера которых используется код отслеживания ? Utm_medium .
Пользовательский агент: Adsbot-Google Allow: / *? Utm_medium = * Пользовательский агент: AdIdxBot Allow: / *? Utm_medium = * Пользовательский агент: Facebot Allow: / *? Utm_medium = *
Вы можете найти более подробную информацию о каждом из этих сканеров по следующим ссылкам:
Отфильтрованные / граненые URL и ловушки для сканирования
Если у вас большой веб-сайт с расширенной функциональностью (например, отфильтрованные и ограненные URL-адреса на страницах категорий), просмотрите ваш сайт с помощью имитатора поискового бота, такого как Кричащая лягушка может помочь раскрыть некоторые потенциальные ловушки для поисковых систем.
После завершения сканирования найдите шаблоны URL-адресов, которые явно не являются качественными страницами, которые поисковые системы должны сканировать и индексировать. Запишите для них символы подстановки «Disallow» в файле robots.txt, чтобы поисковые системы не тратили свое время на их сканирование (и не на полное сканирование контента, который вы действительно хотите сканировать и индексировать). Одна из самых распространенных ловушек, которые я видел, это отфильтрованные / ограненные URL.
Используйте мой оптимизированный файл WordPress Robots.txt
Я приветствую вас использовать мой файл WordPress robots.txt как шаблон. Я неоднократно проверял его, чтобы убедиться, что мои правила не блокируют какой-либо важный контент, а также что Google может сканировать мои файлы JavaScript или CSS. Не стесняйтесь использовать его в качестве отправной точки, но обязательно используйте Просмотреть как Google а также Robots.txt Tester инструменты в консоли поиска Google, чтобы настроить его для вашего конкретного сайта. Вы также захотите настроить URL-адрес XML-карты сайта (конечно!).
Есть вопросы? Оставьте их в комментариях, и я буду рад ответить на них.
Похожие
WordPress SEO: создание Google SitemapЗдравствуйте, читатели Мастер Агентства! На прошлой неделе в одном из серия о SEO в WordPress Я показал важность создания карта сайта для вашего блога WordPress , Многие могут подумать: «Вот! Теперь у всех поисковых систем есть место, чтобы увидеть все страницы моего сайта ». Эта точка зрения неверна. Существует также Как заменить инструменты SEO на Google
... для работы поисковых систем. Анализ обратных ссылок Инструменты обратной ссылки, безусловно, ценны, и я не хочу сказать, что они не должны использоваться. Но на самом деле вы можете получить много информации о том, сколько сайтов ссылаются на кэшированные страницы, просто используя Google. Ваш подход будет зависеть от размера сайта, на который вы ориентируетесь. Если вы нацелены на других SEO-специалистов, поиск в Google точного URL-адреса Как создать файл Sitemap в WordPress (XML и HTML)
... воем сайте WordPress, но он полезен только в том случае, если люди и поисковые системы действительно могут его найти"> Вы создаете много отличного контента на своем сайте WordPress, но он полезен только в том случае, если люди и поисковые системы действительно могут его найти. Файлы Sitemap помогают вам достичь этого, по сути предоставляя людям и поисковым системам «карту» всего контента на вашем «сайте» ( отсюда и название ). Это делает их важным инструментом как Что такое XML Sitemap?
... URL-адресов на веб-сайте. Он может включать в себя дополнительную информацию (метаданные) по каждому URL, а также информацию о том, когда они последний раз обновлялись, насколько они важны и есть ли какие-либо другие версии URL, созданные на других языках. Все это делается для того, чтобы поисковые системы могли более эффективно сканировать ваш веб-сайт, позволяя напрямую вносить в них любые изменения, в том числе при добавлении новой страницы или удалении старой. Нет никакой гарантии, Почему важны глубокие ссылки?
Для развития мобильного интернета глубокие ссылки означали не что иное, как размещение обратных ссылок на более глубокие страницы на веб-сайте, помимо домашней страницы. Теперь глубокие ссылки также можно интерпретировать как ссылки, которые непосредственно ссылаются на приложение Также интересно, но в этой статье мы рассмотрим влияние размещения обратных ссылок на более глубокие страницы на ранжирование ключевых Обновление Google Hawk и влияние на SEO
Кажется, 22 августа 2017 года Google выпустил большое обновление алгоритма. Сообщество SEO назвало обновление «Ястреб». В этом блоге вы узнаете все об этом обновлении и влиянии на вашу компанию. Что такое Google Hawk? Каково влияние Google Hawk? Что мне теперь делать? Почему это называется Ястреб? Что такое Google Hawk? Hawk - это название обновления алгоритма Google, которое было выпущено 22 августа 2017 года. Что такое SEO-хостинг? И действительно ли это касается IP-адресов C-класса?
... для SEO, бесполезны. Какой бы сайт вы ни разработали, он должен быть оптимизирован для SEO. Вы можете привлечь посетителей; поднять ваши продажи, если ваш сайт оптимизирован для SEO. SEO использует как традиционный, так и нетрадиционный процесс для повышения вашего сайта. Что такое IP C-класса? Каждый сайт имеет определенный IP-адрес. Используя этот IP-адрес, вы можете найти свой сайт в Интернете. Всякий раз, когда вы размещаете сайт, вы получите IP-адрес. С Что означает NAP и помогает ли это местному SEO?
... вание в локальных органических результатах поиска, потому что поисковые системы, такие как Google, учитывают данные при определении того, какие компании следует показывать для поисковых запросов с географической ориентацией. Что могут сделать компании с помощью NAP, чтобы повысить свой рейтинг в поисковой сети? Для начала убедитесь, что ваш NAP правильный - как на вашем сайте, так и на других сайтах в Интернете. Местные эксперты по SEO считают, что Google и другие поисковые [Инструменты] SEO SpyGlass
Анализ ссылок - это широкая тема, которая не заканчивается поисковой консолью. Особенно, когда речь идет об анализе конкурентных ссылок, к которым у нас нет доступа в Search Console. Мы сразу придумываем такие решения, как Majestic или Ahrefs, но они не лишены одного большого недостатка. Эти инструменты популярны, поэтому очень часто блокируются в подсобных помещениях и не только. Предполагается, что многие веб-сайты блокируют свои сканеры из-за ресурсов, которые они едят. И тут приходит Что такое SEO специалист: описание работы
Изображение Бизнесмен работает с ноутбуком в офисе из Shutterstock Специалист по поисковой оптимизации (SEO) анализирует, анализирует и вносит изменения в веб-сайты, чтобы оптимизировать их для поисковых Robots.txt
... txt текстовый файл и как его можно использовать для инструктирования поисковых роботов. Этот файл особенно полезен для управление обходом бюджета и убедитесь, что поисковые системы эффективно проводят время на вашем сайте и сканируют только важные страницы. Для чего нужен текстовый файл роботов?
Комментарии
Но что это такое и почему это важно для вас?Но что это такое и почему это важно для вас? Поисковая оптимизация, или SEO, оптимизирует контент вашего сайта для поисковых систем. Что это значит? Это означает, что Google и другие поисковые системы могут легко проиндексировать ваш контент, классифицировать ваши страницы на основе их контента, а затем сделать эти страницы доступными для людей, ищущих ваш конкретный контент. SEO важно, потому что вы хотите, чтобы люди легко находили ваш контент, продукт или услугу. Для маркетологов Как это изменило влияние первичной недвижимости на поисковую выдачу Google и как это влияет на то, где люди нажимают, когда попадают на поисковую выдачу Google?
Как это изменило влияние первичной недвижимости на поисковую выдачу Google и как это влияет на то, где люди нажимают, когда попадают на поисковую выдачу Google? Конечно, это зависит от типа поиска, который проводит пользователь, но исторически сложилось так, что вы действительно хотите быть найденным в этой главной сфере поисковой выдачи. Ранее мы определили некоторые из этой главной недвижимости как Золотой треугольник Google, где три или четыре лучших результата в поисковой выдаче - это то место, 1. Что такое полномочия домена и почему это важно?
1. Что такое полномочия домена и почему это важно? Domain Authority (DA) - это показатель силы веб-сайта, основанный на различных показателях. Основные показатели, которые увеличивают DA сайта, включают в себя: Ваши социальные профили, указывающие на сайт И количество качественных ссылок и общие усилия по SEO. И как это произведет большое впечатление на то, что ваши участники, клиенты и спонсоры захотят открыть свои кошельки и заплатить за ваш живой контент, а не за другую конференцию?
И как это произведет большое впечатление на то, что ваши участники, клиенты и спонсоры захотят открыть свои кошельки и заплатить за ваш живой контент, а не за другую конференцию? Вот несколько советов, чтобы убедиться, что ваше событие отображается поисковыми системами: Используйте одно и то же доменное имя (другими словами, адрес веб-сайта перед .com или .org) для вашего мероприятия каждый год. Вы получите авторитет домена, потому что Google взвешивает домены, Поскольку в результатах поиска Google есть высокий уровень по вашему вопросу «что такое SEO-поисковая оптимизация?
Поскольку в результатах поиска Google есть высокий уровень по вашему вопросу «что такое SEO-поисковая оптимизация?», То вы видите, что у меня есть знания, чтобы правильно обработать эти результаты Google. Идти выше в гугле? Быть доступным для вашего потенциального клиента - важная задача, как часть вашего общего видения онлайн маркетинга. Поиск в Google играет важную роль в этом. Но у меня есть хороший сайт! Хороший сайт хорош, но если вы не Что такое SEO и почему это важно?
Что такое SEO и почему это важно? Поисковая оптимизация (SEO) - это набор методов и стратегий, которые помогают улучшить веб-сайты и рейтинги контента в результатах поисковых систем, что ведет к повышению видимости и увеличению органического трафика. Это просто метод оптимизации кода и форматирования вашего сайта, чтобы поисковые системы могли его легче найти. Просто подумай об этом. Когда вы ищете что-то в Google, вам нужна только самая актуальная информация для ваших Что такое исследование ключевых слов и почему это так важно?
Что такое исследование ключевых слов и почему это так важно? Изучение ключевых слов помогает нам определить эти стратегические и соответствующие термины для органического (а не органического) позиционирования веб-страницы . Он состоит из знания того, что и как ищут пользователи, когда дело доходит до вопросов, связанных с деятельностью моего сайта. Благодаря исследованию ключевых слов у нас есть возможность адаптировать наш сайт к тому, что ищут Что такое Google Пингвин?
Что такое Google Пингвин? Google выпустил обновление алгоритма поиска в апреле 2012 года под названием Penguin. Цель этого обновления - поймать веб-сайты, которые манипулируют поисковыми рейтингами и спамом, путем создания ссылок с помощью массовых и спам-методов с целью повышения рейтинга в результатах поиска (страницы результатов поисковой системы). Поскольку обратные ссылки являются одним из ключевых факторов ранжирования, который Google рассматривает, чтобы Что такое веб-сайты и как / почему они их выбрали?
Что такое веб-сайты и как / почему они их выбрали? Это топ-1000 на Alexa или Compete.com или что? SERPMetrics Похоже, что сайты только в США. Не могу найти, как они собирают свои данные. Когда мне нужна информация о том, что происходит в моей нише, вышеупомянутые услуги просто дают мне «ОК» опыт. Ни один из них действительно не дает мне понимание моей ниши или моего ключевого слова. Как вы оцениваете, что такое стандартный рейтинг кликов для определенного ключевого слова?
Как вы оцениваете, что такое стандартный рейтинг кликов для определенного ключевого слова? Ларри Ким: Да, существуют разные кривые CTR для разных поисковых терминов. Я поделился данными для 1000 различных поисковых терминов для одного веб-сайта в одной отрасли (интернет-маркетинг). Кривые резко меняются в зависимости от ниши запроса. Например, ключевые слова для покупок обычно имеют такие огромные рекламные объявления, которые снижают органический CTR, потому Была ли это настоящая бомба Google или просто признак того, что алгоритм Google действительно становится намного умнее?
Была ли это настоящая бомба Google или просто признак того, что алгоритм Google действительно становится намного умнее? Я не мог прокомментировать (я не хотел бы расстраивать общеизвестно гиперчувствительный церковь), и даже если бы я хотел, я не думаю, что мои взгляды могут быть сформулированы лучше, чем Мистер Джон Суини (обязан посмотреть). Сильвио Берлускони
Txt?
Почему это важно?
Txt?
Почему это важно?
Разрешить: / *?
Пользовательский агент: Adsbot-Google Allow: / *?
Utm_medium = * Пользовательский агент: AdIdxBot Allow: / *?
Utm_medium = * Пользовательский агент: Facebot Allow: / *?
Есть вопросы?
Что такое Google Hawk?