
Окончательное руководство по поиску и устранению вздутия индекса
- Что такое индекс Bloat? Раздувание индекса является одной из наиболее распространенных проблем SEO,...
- Как я узнаю, что мой сайт испытывает вздутие индекса?
- Фиксация индекса
- Meta Robots Tag
- Файл Robots.txt
- Перенаправление
- Канонизация
- пагинация
- Инструмент URL-параметров
- Инструмент для удаления URL
- Фиксация индекса
- Автор: Джон Кайоззо
Что такое индекс Bloat?
Раздувание индекса является одной из наиболее распространенных проблем SEO, с которыми сегодня сталкиваются веб-сайты, особенно сайты электронной коммерции.
Это происходит всякий раз, когда Google индексирует страницы, которые не должны быть проиндексированы. Раздувание индекса может произойти практически с любым веб-сайтом в результате проблем с разбиением на страницы, индексацией защищенных и небезопасных версий вашего сайта или даже разрешением Google индексировать категории, теги и архивы блогов WordPress.
Сайты электронной коммерции являются наиболее распространенным виновником вздутия индекса. Большинство сайтов электронной коммерции имеют списки фильтров или виджеты, которые позволяют пользователям быстро находить продукты, соответствующие их спецификациям. Например, в Amazon есть фильтры «Средняя оценка клиента» или «Самая низкая цена». Однако такие фильтры обычно создают новые страницы после того, как пользователь выберет конкретные параметры. Когда Google посещает веб-сайт, он обычно следует всем ссылкам и кнопкам на веб-странице, включая фильтры, которые могут привести к тому, что он будет индексировать тысячи страниц, не представляющих уникальной ценности для Google или пользователей.
Почему проблема с раздуванием индекса?
Раздувание индекса может быть огромной проблемой SEO для вашего сайта. С одной стороны, это сбивает с толку поисковые системы, особенно когда есть потенциально тысячи вариантов одной категории продукта. Когда поисковые системы сталкиваются с веб-сайтом с раздуванием индекса, они могут изо всех сил пытаться понять, какая страница является наиболее релевантной для поисковиков и может предоставить не релевантные результаты - то, чего Google хочет избежать любой ценой.
Индекс вздутия также вызывает проблемы с дублированным контентом , поскольку эти страницы обычно не имеют уникального содержания или метаинформации. Помните, это то, что Google говорит о дублированном контенте:
Дублированный контент обычно относится к существенным блокам контента внутри или между доменами, которые либо полностью совпадают с другим контентом, либо заметно схожи. Главным образом, это не обманчиво по происхождению.
Несмотря на то, что дублированный контент не является основанием для того, чтобы Google пытался вас заполучить, он не оказывает никакого содействия вашему сайту. На самом деле, гораздо лучше сделать ваш контент и метаинформацию уникальной, поскольку Google предпочитает показывать страницы, которые будут предлагать пользователям полезный контент, который они не смогут найти где-либо еще. Все это способствует улучшению взаимодействия с пользователем.
Раздувание индекса также может снизить бюджет и частоту сканирования, не позволяя Google сканировать и индексировать важные страницы и разделы вашего сайта. Если Google сосредоточится на неправильных страницах, это может привести к значительному снижению рейтинга, трафика и, в конечном итоге, конверсий.
Как я узнаю, что мой сайт испытывает вздутие индекса?
Если вы подозреваете, что вздутие индекса является причиной недавней потери рейтинга, есть простой способ выяснить это. Одним из признаков раздувания индекса является чрезмерное количество проиндексированных страниц - число, намного превышающее количество страниц, которые, по вашему мнению, должны были проиндексировать Google. Если ваш индекс недавно испытал какие-либо колебания, вы можете стать жертвой.
Перейдите в консоль поиска Google и нажмите «Статус индекса» в разделе «Индекс Google». Вы можете увидеть что-то вроде этого:
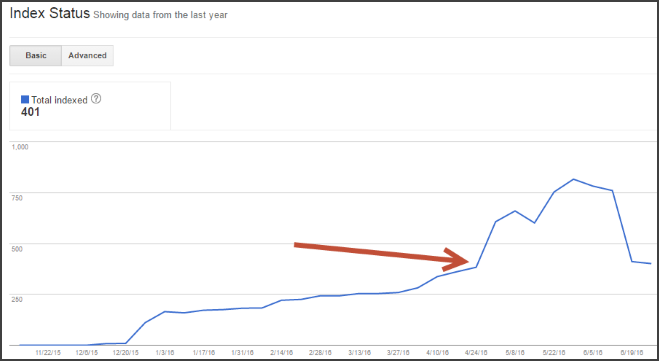
В этом конкретном примере мы заметили быстрый рост числа проиндексированных страниц, начиная с конца апреля.
Однако, как правило, найти раздувание индекса не так просто, и, как правило, требуется больше выяснить, действительно ли это происходит или нет. Веб-сайты могут не иметь каких-либо недавних колебаний в размере индекса, или у них может отсутствовать подозрительное количество проиндексированных страниц. В этих случаях вы можете продолжить расследование, ведя сайт: в Google.
Вот пример, который мы сделали для Forbes:
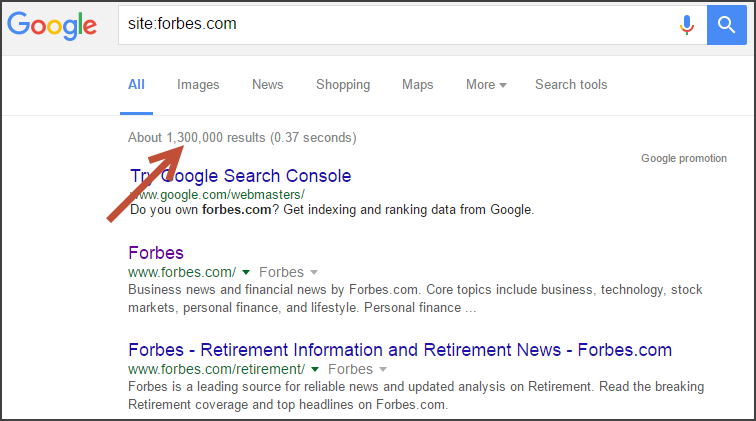
С помощью оператора site: вы ограничиваете поиск только указанным веб-сайтом. В этом примере вы можете видеть, что Google использует приблизительно 1 300 000 страниц из Forbes, которые были проиндексированы. (Важно отметить, что номера индексов в Google Search Console и Google.com обычно не совпадают, но они близки.)
Итак, теперь, когда мы провели сайт: поиск, нам нужно просмотреть каждую страницу результатов поиска Google, чтобы найти общую тему в параметрах или страницах, которая может вызывать вздутие индекса. Иногда вы можете ускорить этот процесс, переходя к последним страницам результатов поиска, так как Google обычно хранит наименее релевантные результаты на последних страницах. Вот так:
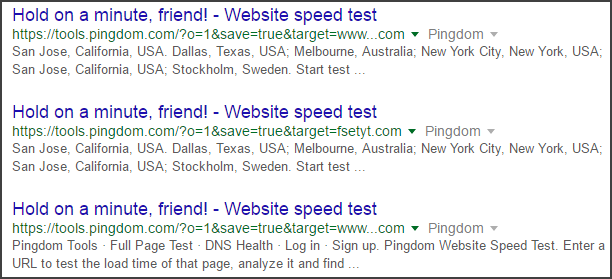
В этом случае мы обнаружили почти сотню страниц, проиндексированных Google с pingdom.com, где были сохранены тесты скорости страниц. Эти страницы не добавляют Pingdom никакой ценности в отношении SEO, поскольку у них нет уникального заголовка, метаинформации или контента (кроме статистики времени загрузки страницы для доменов). Это те типы страниц, на которые вы хотите обратить внимание в своем индексе Google, потому что они без необходимости увеличивают размер вашего индекса, истощают ресурсы поисковой системы и запутывают поисковые системы.
Фиксация индекса
Теперь, когда мы определили некоторые проблемные страницы, мы можем запретить поисковым системам индексировать эти страницы несколькими различными способами, тем самым уменьшая раздувание индекса вашего сайта. Важно отметить, что, хотя иногда можно использовать только один из этих методов, более крупным веб-сайтам может потребоваться их сочетание для надежного решения проблемы.
Meta Robots Tag
Мета-тег robots - это один из лучших вариантов быстрого сокращения индекса, поскольку он имеет приоритет над robots.txt, нумерацией страниц и канонизацией. Тэг meta robots можно использовать, чтобы явно указать поисковым системам, какие страницы они имеют и не могут индексировать. Когда вы сталкиваетесь с типом страницы, который не должен быть проиндексирован, все, что вам нужно сделать, это просто добавить следующий код в заголовок:
< META NAME = "ROBOTS" CONTENT = "NOINDEX, FOLLOW">
(Примечание: в некоторых случаях это может быть необходимо сделать программно.)
Указывая «NOINDEX, FOLLOW», вы говорите поисковым системам, что им не следует индексировать страницу, но они могут свободно переходить по любым ссылкам на этой странице. Это гарантирует, что поисковые системы могут по-прежнему получать доступ к остальной части вашего сайта без индексации самой страницы.
Файл Robots.txt
Ваш файл robots.txt может использоваться, чтобы сообщать поисковым системам и другим роботам, какие области (или параметры) вашего веб-сайта им разрешено сканировать.
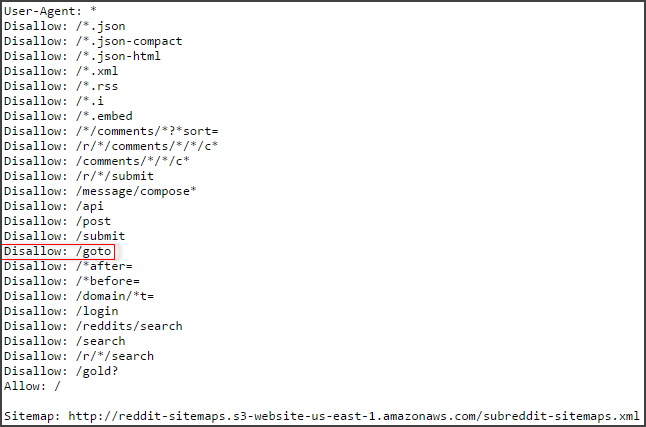
Как видно выше, параметры и URL-адреса могут быть заблокированы с помощью директивы disallow. Однако важно отметить, что когда вы блокируете Google с помощью файла robots.txt, ваш сайт все же может быть проиндексирован.

Мы знаем, что вы думаете: «Подожди, что? Я думал, что с помощью «запретить» Google был заблокирован с этих страниц! »
Это почти правда. В действительности файл robots.txt не позволяет Google сканировать страницу, но индексирование страницы все еще возможно, особенно если страница связана с другой веб-страницей, которая не заблокирована вашим файлом robots.txt. Если вы знаете, где эти страницы связаны, вы можете легко запретить Google индексировать их, сделав ссылки на эту страницу «nofollow».
Средство удаления URL-адресов Google в консоли поиска Google может оказаться полезным для удаления этих страниц из индекса Google после того, как будут приняты соответствующие меры, чтобы гарантировать, что они не будут повторно проиндексированы.
Перенаправление
Некоторое увеличение индекса может быть вызвано старыми веб-страницами, которых больше нет на вашем сайте. Они могут решить как 404 ошибки. Со временем Google в конечном итоге удалит эти страницы из своего индекса, но кто знает, сколько времени это может занять? Вы можете ускорить процесс и дать Google дополнительный толчок для удаления этих старых веб-страниц из своего индекса, перенаправив их на самую релевантную страницу. Это также гарантирует, что вы сократите количество ссылочного сока, которое вы теряете на этих страницах.
Канонизация
Канонический тег используется, чтобы сообщить поисковым системам, какая версия страницы является предпочтительным URL для индексации. Это особенно полезно, когда у вас есть несколько URL для одного и того же контента. Добавление канонического тега в заголовок указывает, какую версию страницы должны индексировать поисковые системы. Просто убедитесь, что все версии страницы, включая предпочитаемую страницу, должны указывать на один и тот же предпочтительный канонический URL.
пагинация
Разбиение на страницы обычно происходит, когда у вас есть более одной страницы категорий продуктов, сообщений в блоге или результатов поиска на странице. Поскольку эти страницы содержат одну и ту же метаинформацию, вы должны сообщить поисковым системам о взаимосвязи между страницами, чтобы они не идентифицировались как дублированный контент.
Добавление разметки нумерации страниц также уменьшит количество индексируемых страниц, поскольку поисковые системы будут лучше понимать взаимосвязь между страницами и будут знать, какие из них следует проиндексировать или нет.
Добавить нумерацию страниц к своим заголовкам на этих страницах довольно просто. Например, если у вас есть страница, такая как http://www.example.com/blog?category=seo&page=2 тогда вы добавите следующие теги в свой заголовок:
< link rel = "prev" href = "http://www.example.com/blog?category=seo&page=1" /> < link rel = "next" href = "http://www.example.com/ blog? category = seo & page = 3 "/>
Инструмент URL-параметров
Инструмент URL-параметров в консоли поиска Google можно использовать, чтобы сообщить Google, что ваши параметры URL-адреса влияют на содержание ваших страниц. Этот инструмент влияет только на результаты поиска Google, поэтому его следует действительно использовать только в том случае, если предыдущие методы не помогли или не являются приемлемыми. Как и многие методы, перечисленные в этой статье, вы должны быть очень осторожны, чтобы случайно не исключить URL-адреса, которые должны быть проиндексированы, или указать неверное поведение для параметров, поскольку это может негативно повлиять на ваши усилия по SEO.
В Инструменте параметров URL Google классифицирует ваши параметры на две основные категории - активные параметры и пассивные параметры. Как вы, вероятно, догадались, активные параметры изменяют то, что отображается на странице, тогда как пассивные параметры не влияют на содержимое, отображаемое на странице (источник UTM, идентификаторы сеанса и т. Д.).
С определенным активным параметром может быть связано несколько действий, таких как разбиение на страницы, перевод, сортировка, сужение и указание. Вы также можете указать несколько опций относительно того, какие URL и значения параметров также являются целевыми. Если вы еще не знакомы с этим инструментом, настоятельно рекомендуем прочитать Документация Google так что вы хорошо понимаете, что делает каждое действие.
Инструмент для удаления URL
Индекс Google иногда бывает довольно упрямым. Даже после того, как вы попробовали некоторые из указанных выше методов, вы все равно можете найти страницы в индексе Google, которых просто не должно быть. Чаще всего это происходит, когда страница заблокирована с помощью robots.txt, и Google все равно индексирует ее, поскольку она связана с другой страницей вашего сайта. Добавление тега nofollow к этой ссылке может предотвратить это, но даже в этом случае вы можете обнаружить, что страницы не удалены из поисковой выдачи Google. Расстраивает, нет?
В подобных ситуациях вы всегда можете воспользоваться инструментом удаления URL-адресов в консоли поиска Google. Использование этого инструмента позволяет запрашивать у Google удаление определенных URL из своего индекса. Запросы обычно обрабатываются в тот же день, когда они запрашиваются, поэтому это может быть быстрый способ выбить все оставшиеся URL-адреса, которые не должны были быть проиндексированы, если все другие методы не сработали.
Важно отметить, что это временная мера; если вы не предприняли никаких мер для предотвращения повторной индексации этих страниц в будущем, то они вернутся к индексу Google, когда Google будет сканировать ваш сайт в будущем.
Фиксация индекса
Теперь у вас есть инструменты и знания, чтобы не только найти, но и решить проблему раздувания индекса. Теперь вы должны взглянуть на свой собственный веб-сайт и посмотреть, если он испытывает симптомы. После того, как вы определили проблему, воспользуйтесь некоторыми или всеми из следующих методов, чтобы устранить ее:
- Мета-робот
- Файл Robots.txt
- 301 переадресация
- Канонизация
- пагинация
- Инструмент URL-параметров
- Инструмент для удаления URL
Используя комбинацию этих методов или все эти методы, вы сможете представить свой сайт в Google таким образом, чтобы он соответствовал их требованиям и позволил вам получить заслуженный рейтинг.
Примечание . Мнения, выраженные в этой статье, являются мнением автора, а не обязательно мнением Caphyon, его сотрудников или партнеров.
Автор: Джон Кайоззо
Джон Кайоццо является SEO-аналитиком в SEO Inc. одна из ведущих компаний в мире по поисковой оптимизации в мире с 1997 года. Джон специализируется на создании передовых технических решений и стратегий SEO для увеличения трафика и конверсий на клиентские сайты. Просмотреть все сообщения от John Caiozzo
Похожие
Что такое SEO специалист: описание работыИзображение Бизнесмен работает с ноутбуком в офисе из Shutterstock Специалист по поисковой оптимизации (SEO) анализирует, анализирует и вносит изменения в веб-сайты, чтобы оптимизировать их для поисковых Как взломать алгоритм SEO
Когда вы слышите слово «алгоритм», ваши глаза могут начать глазеть, как это было в вашем классе алгебры в старшей школе, но алгоритмы поиска более важны для вас, чем нахождение «х». Понимание того, что стоит за алгоритмами, которые стимулируют поиск, очень важно. - особенно если учесть, что около 2/3 посетителей веб-сайта приходят из органического поиска. Более сильное цифровое присутствие помогает вашей поисковой оптимизации (SEO), что, в свою очередь, приведет клиентов на ваш сайт и, в конечном Как продать свои локальные услуги SEO, как Rockstar
Давайте будем честными - мы все скептически относимся к страшной рекламной подаче. Сверхобещающие обещания, гипербола, приманка Земли Обетованной, которая не может быть доставлена. Вместо того, чтобы продавать им печенья, репетировали коммерческое предложение, предоставьте решение их проблемы. # 1 - Сделайте свою домашнюю работу о бизнесе, прежде чем идти на встречу или подготовиться отправить SEO услуги в Кру, Чешир
Повысьте свой рейтинг и узнаваемость в поисковых системах - увеличьте трафик, потенциальных клиентов и продажи! Если у вас есть веб-сайт и на нем не была проведена поисковая оптимизация, то вы также можете пытаться скрыть свой веб-сайт от всего мира. Сегодняшние профессионалы Поисковая оптимизация (SEO)
... что поисковая оптимизация не применяется должным образом или профессионально, чтобы сделать ее еще более эффективной. Обычно это происходит из-за того, что нет времени или экономии для инвестиций в поисковую оптимизацию или что у вас плохой опыт работы с SEO-консультантами, которые не могут управлять своими вещами. С нашими пять SEO-пакетов Вы уверены, что ваши клиенты найдут вас лучше, чем когда-либо. Сайт | SEO - Оптимизация сайта
Узнайте текущую позицию вашего сайта Просто заполните следующую форму введите свой домен в поле веб-страницы - например: vasestranky.cz в поле ключевых слов введите слово или фразу, которую вы хотите найти. выберите поисковик отправь это Форма ищет только первые 20 страниц для повышения производительности. Что такое SEO? Нанять SEO Эксперт
Главная >> Сервисы >> Интернет-продвижение >> Нанимайте SEO Expert «Получите высококлассные услуги SEO от SEO-экспертов Webeveron» . Хорошо спроектированный сайт без профессионалов в области поисковой оптимизации - это продукт, который никогда не рекламировался. электронная книга: SEO для агентств - как использовать технику для получения результатов
SEO является одной из стратегических и фундаментальных частей цифрового маркетинга. Генерация результатов без SEO практически невозможна. Использование методов SEO приобретает все большую актуальность и становится критически важным для компаний, которые лучше позиционируются в поисковых системах и могут быть найдены потенциальными клиентами, что увеличивает деловые шансы. Это связано с тем, что такие методы способны максимизировать результаты, особенно в области Начало Facebook SEO
Последняя проверка 6 марта 2019 года в 18:54 Как мы все знаем, Facebook быстро догоняет свой рейтинг трафика Как заменить инструменты SEO на Google
... что SEO Не волнуйтесь, я не защищаю возвращение к бумажному SEO затоплен так много инструментов, которые не нужны в принципе. Они просто собирают информацию, которую вы можете получить сами, и предоставляют слишком много данных, чем вам действительно SEO услуги - на странице SEO - на странице SEO | Ticode
Вы уже знаете, что ваш сайт не имеет хорошего рейтинга в поисковых системах, и вы, вероятно, знаете некоторые из причин, почему. Возможно, мы даже выполнили полный SEO Оценка сайта для вас, и теперь мы готовы реализовать некоторые или все изменения, рекомендованные в нашем отчете. Если оценка не проводилась, мы проведем подробное интервью с вами, чтобы узнать больше о вашем рынке, прежде чем мы начнем какую-либо оптимизацию вашего
Комментарии
Само «О» в «SEO» - это оптимизация, и уже поговорим об этом @ 365tipu находится в Что такое SEO?Как я узнаю, что мой сайт испытывает вздутие индекса? Если вы подозреваете, что вздутие индекса является причиной недавней потери рейтинга, есть простой способ выяснить это. Одним из признаков раздувания индекса является чрезмерное количество проиндексированных страниц - число, намного превышающее количество страниц, которые, по вашему мнению, должны были проиндексировать Google. Если ваш индекс недавно испытал какие-либо колебания, вы можете стать жертвой. Перейдите в Что такое SEO SEO?
Что такое SEO SEO? Поисковая оптимизация (SEO) - это постоянно меняющаяся практика разработки веб-контента, который будет высоко оцениваться на страницах результатов поисковой системы (SERP). Поскольку поиск часто контролирует ваш контент, оптимизация вашего сайта для поиска необходима для привлечения трафика и увеличения числа подписчиков. SEO в SEO включает в себя оптимизацию вашего канала, плейлистов, метаданных, описания и самих видео. Вы можете оптимизировать свои Итак, что такое Advanced Barnacle SEO и как вы можете его использовать?
Итак, что такое Advanced Barnacle SEO и как вы можете его использовать? Обычно я не решаюсь поделиться этим с SEO, потому что я видел, как некоторые SEO используют это для зла. Хорошая новость заключается в том, что с продвинутыми алгоритмами Google я чувствую себя все более и более комфортно каждый день, когда люди, которые пытаются манипулировать этим, будут пойманы. При этом давайте перейдем прямо. Усовершенствованная SEO Barnacle, на мой взгляд, намного больше влияет на традиционные Как бы вы хотели, чтобы поисковая система считала, что ваша веб-страница является наиболее релевантной для определенного запроса, если на ней нет содержимого?
Как бы вы хотели, чтобы поисковая система считала, что ваша веб-страница является наиболее релевантной для определенного запроса, если на ней нет содержимого? Чтобы сослаться на запрос, у вас должна быть страница, которая отвечает намерению пользователя с качественный контент , Под качеством мы подразумеваем уникальный, актуальный, структурированный контент, достаточно длинный и без ошибок. Итак, как именно видео-маркетинг влияет на SEO вашего сайта, и как вы можете использовать его в своей стратегии контент-маркетинга?
Итак, как именно видео-маркетинг влияет на SEO вашего сайта, и как вы можете использовать его в своей стратегии контент-маркетинга? Ниже приведены четыре ключевых показателя SEO и некоторые рекомендации по использованию видео для повышения рейтинга в поисковых системах: Рейтинг видео в поисковой выдаче Ранжирование на первой странице Google является первоочередной задачей SEO, поэтому трудно игнорировать исследование Forrester 2009 года, в котором говорится, что «страницы Итак, после того, как вы узнали, что получение бесплатного органического трафика с помощью поиска Google на самом деле не вариант, как вы планируете привлекать клиентов на свой веб-сайт?
Итак, после того, как вы узнали, что получение бесплатного органического трафика с помощью поиска Google на самом деле не вариант, как вы планируете привлекать клиентов на свой веб-сайт? » В приведенной цитате из Остин Лоусон Ясно, что Google контролирует подавляющее большинство результатов поиска ваших клиентов. Это 800-фунтовая горилла. Может быть, вы не беспокоитесь о результатах поисковых систем для ваших событий, вместо этого, используя Но как насчет небольших сайтов, таких как небольшой личный блог или сайт электронной коммерции, ориентированных на относительно небольшое количество продуктов или услуг?
Но как насчет небольших сайтов, таких как небольшой личный блог или сайт электронной коммерции, ориентированных на относительно небольшое количество продуктов или услуг? Должен ли этот тип сайта также интегрировать панировочные сухари? На этот вопрос нет правильного или неправильного ответа. Хотя очевидно, что хлебные крошки предпочитают SEO для больших сайтов со сложной древовидной структурой, их релевантность в этой области априори менее важна для сайтов небольшого Но что такое SEO?
Но что такое SEO? Какие меры подпадают под SEO, а какие - «нормальные оптимизации», то есть те, которые не реализованы для машин, но для использования людьми? Насколько важен SEO для успеха сайта? Создавать сайты для людей или машин? Сайты созданы для людей. Даже если SEO стремится к лучшему ранжированию в поисковых системах, это, в конечном счете, люди (должны) через Google и Co. на сайте. Поэтому при создании сайта основное внимание всегда следует уделять пользователям, Что такое поисковая оптимизация (SEO)?
Что такое поисковая оптимизация (SEO)? Что ж, SEO помогает таким сайтам, как ваш, появляться в поисковых системах по определенным поисковым запросам. SEO помогает вам найти потенциальных клиентов, которые могут посетить ваш сайт и купить ваш продукт или услугу. Один из наиболее распространенных вопросов, который задают нам стоматологи и врачи: «Сколько мне нужно SEO?
Один из наиболее распространенных вопросов, который задают нам стоматологи и врачи: «Сколько мне нужно SEO?» Вы не можете (разумно) ответить на этот вопрос, не сделав сначала тщательный анализ других стоматологических практик в вашем регионе. Типичный SEO аудит включает в себя: Потребление бизнеса, чтобы наши менеджеры по работе с клиентами видели ваш бизнес с точки зрения владельца Внедрение программного обеспечения для аналитики Им достаточно сложно следить за социальными каналами; как они узнали бы, что является взаимным или уникальным?
Им достаточно сложно следить за социальными каналами; как они узнали бы, что является взаимным или уникальным? Все, что вам нужно сделать, - это использовать свои инструменты SEO и составить список редакторов контента, которые написали аналогичные статьи в социальных сетях и у которых есть хорошие последователи. Обратитесь к ним по электронной почте (или через Twitter) и используйте шаблон электронной почты, как показано ниже: Привет XXX, Меня зовут YYY, и я пишу контент
Что такое индекс Bloat?
Как я узнаю, что мой сайт испытывает вздутие индекса?
Почему проблема с раздуванием индекса?
Как я узнаю, что мой сайт испытывает вздутие индекса?
Мы знаем, что вы думаете: «Подожди, что?
Com/blog?
Com/blog?
Com/ blog?
Расстраивает, нет?
Что такое SEO?